git merge vs git rebase: Avoiding Rebase Hell
Learning Git can be a pain in the ass sometimes (OFTEN). One feature that has continually caused me to pull hair while I was climbing the learning curve is git-rebase. Rebase is a very useful tool, but also gives you more than enough rope to hang yourself with. Several questions need to be answered to fully understand a rebase:
- How exactly does rebase differ from merge?
- When/Why should you use it instead of a merge?
- When should you absolutely not use it?
So first let’s talk about how Git handles a standard merge. A very typical scenario is where you would have one instance of a given repository living on some remote server somewhere acting as the home of your authoritative “master” branch instance. In this situation this is where all code ends up prior to deployment. This could be hosted on github.com or just a $200 linux box sitting under someone’s desk. Either way let’s consider this scenario:
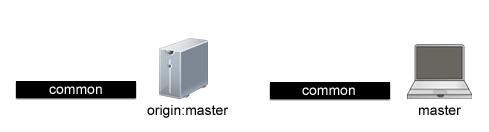
So each black bar represents all of the commits that each instance has in common. In other words we see that our local branch, “master”, and the remote branch that it is tracking, “origin:master”, are both perfectly in sync.
So now the work day has begun and I commit some changes to my local branch instance (red). During this time another developer commits changes to his local branch instance and pushes them up to origin:master (blue). Now the two repositories look like this:
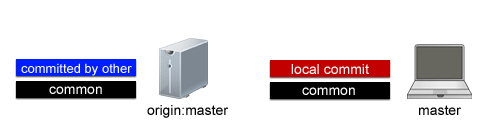
Not knowing that another developer has pushed new changes up to origin:master, I attempt a push myself and am promptly rejected. Realizing that I am not up to date with origin:master I execute the command “git pull origin master”. Git-pull executes a fetch and then a merge all in one command. The result being:

The change that lived on origin but not on my local repository is now merged in. Note the green “merge commit” placed at the top of my hypothetical commit stack. This commit will contain the result of any merge conflicts that you had to resolve. In the case there were no merge problems it is just an empty commit.
Rebase works differently. Given the previous scenario, when we do a pull –rebase (which calls fetch and then rebase instead of merge) it actually un-commits all of your local commits that are not already in origin:master (or whatever branch you are rebasing off of). After it unwinds all your hard work it then stuffs the new commits from the remote branch onto the stack and then plays your changes back on top of them - literally creating a new “base” for which to put your local commits on top of.
If conflicts are found while attempting to play back your changes it throws you into an unnamed branch and gives you a chance to merge everything together. After correcting the conflict(s) you would type “git rebase -continue” as directed by the conflict message. Now we get to the fundamental difference between a merge and a rebase: a rebase ALWAYS gets rid of all your original commits and creates brand new one’s that get placed on top. To say it another way - the original local (red colored) commit is GONE and, as illustrated below, is replaced with a new commit with an entirely different ID (green colored).

If we had two local commits prior to the rebase then we would end up with two brand spanking new commits after a successful rebase - both with new IDs. As far as git is concerned these are new commits…

You may have seen this before:
First, rewinding head to replay your work on top of it...
Fast-forwarded master to fde4b2d5cda60905fcf5973bc17cd051ec2c336d.
It means this quite literally.
When and why should we use Rebase instead of Merge?
Technically speaking you can fully use git without ever using rebase. Merge is perfectly fine for managing your code. When you merge, Git creates the extra commit on top of the stack that we talked about earlier. Git does this in order to track the point at which two diverging repositories have come back together into a common ancestor. This can be quite helpful to be able to, at a glance, tell when and where a parallel branch has been folded back into the master branch. On the other hand, if everyone on a given development team is working from one branch most of the time (say master) then the log can get quite noisy with all of the “merge branch blah” commits from your day to day “git pull origin master” workflow. Using “git pull -rebase origin master” will avoid those superfluous commit messages by pulling and then performing a rebase rather than a merge. This is handy for keeping the appearance of a linear commit history and makes merge commit messages (from other branches) more meaningful because they actually do represent some branch being folded into master.
When should you NEVER use Rebase?
Never, ever, ever do what I will refer to as “lateral rebasing”. What this means is that you should only rebase branches that are authoritative and for which the history will not retroactively change. By “retroactively change” I mean that the branch will only receive, never push them, and commits that are received will always be stacked on top of the last commit… top of the food chain if you will.
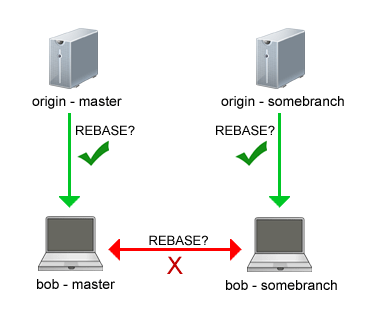
If it’s a local branch you can rebase:
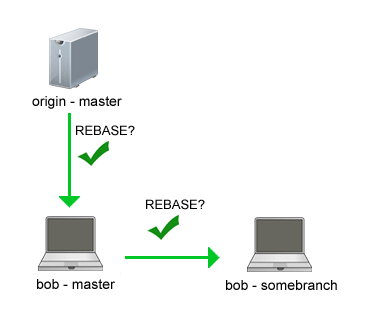
But once the branch is being shared with anyone else it’s time to ditch the rebase and instead use merge to keep your experimental branches up to date with master.
Conclusion:
- Merge works great, but creates lots of empty merge commits when you are working on a team.
- Rebase keeps things tidy, but is destructive and potentially dangerous if you don’t know what you are doing.
Keep yourself safe with a simple rule:
Don’t rebase branches you have shared with another developer.
Do otherwise at your own peril - yes, it will hurt.
